Recognising textual attributes such as bold, italic,
underline and strikeout is essential for understanding text semantics,
structure and visual presentation. Existing methods struggle with computational
efficiency or adaptability in noisy, multilingual settings. To address this, we
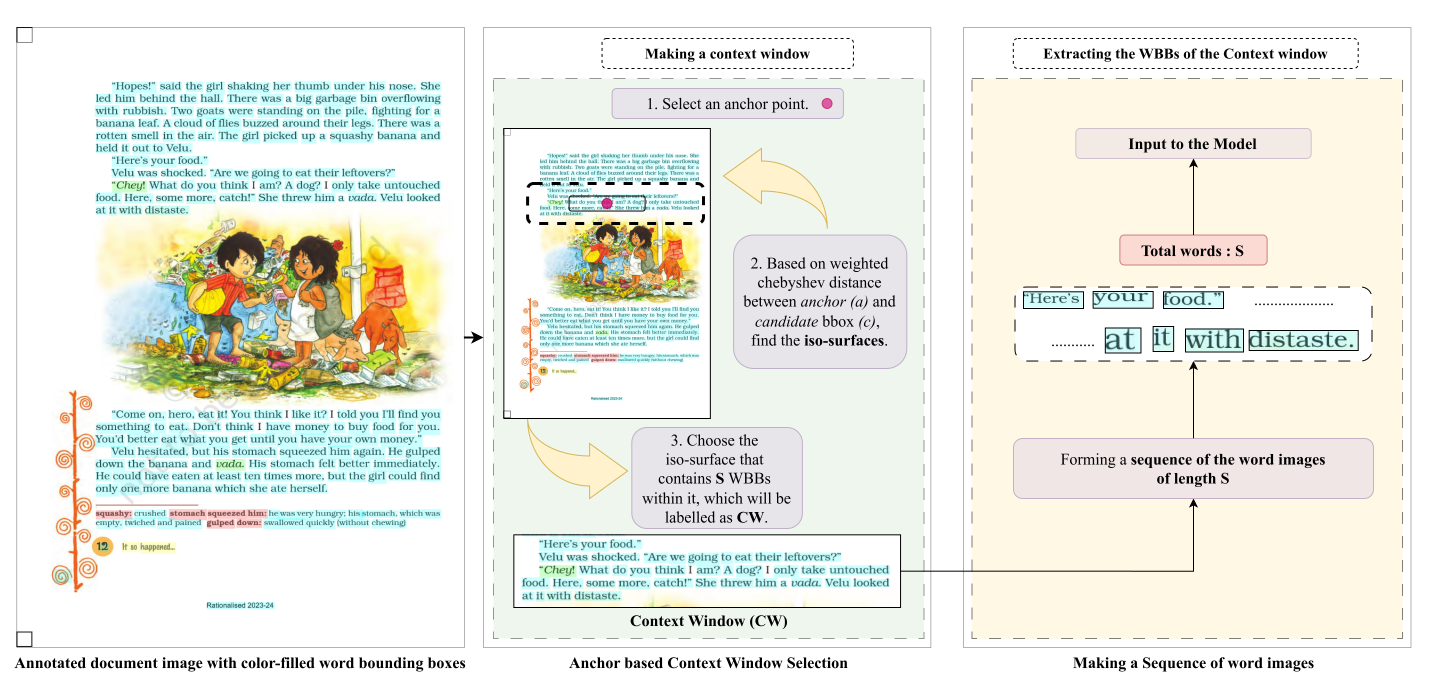
introduce TexTAR, a multi-task, context-aware Transformer for
Textual Attribute Recognition (TAR). Our data-selection pipeline enhances context
awareness and our architecture employs a 2-D RoPE mechanism to incorporate spatial
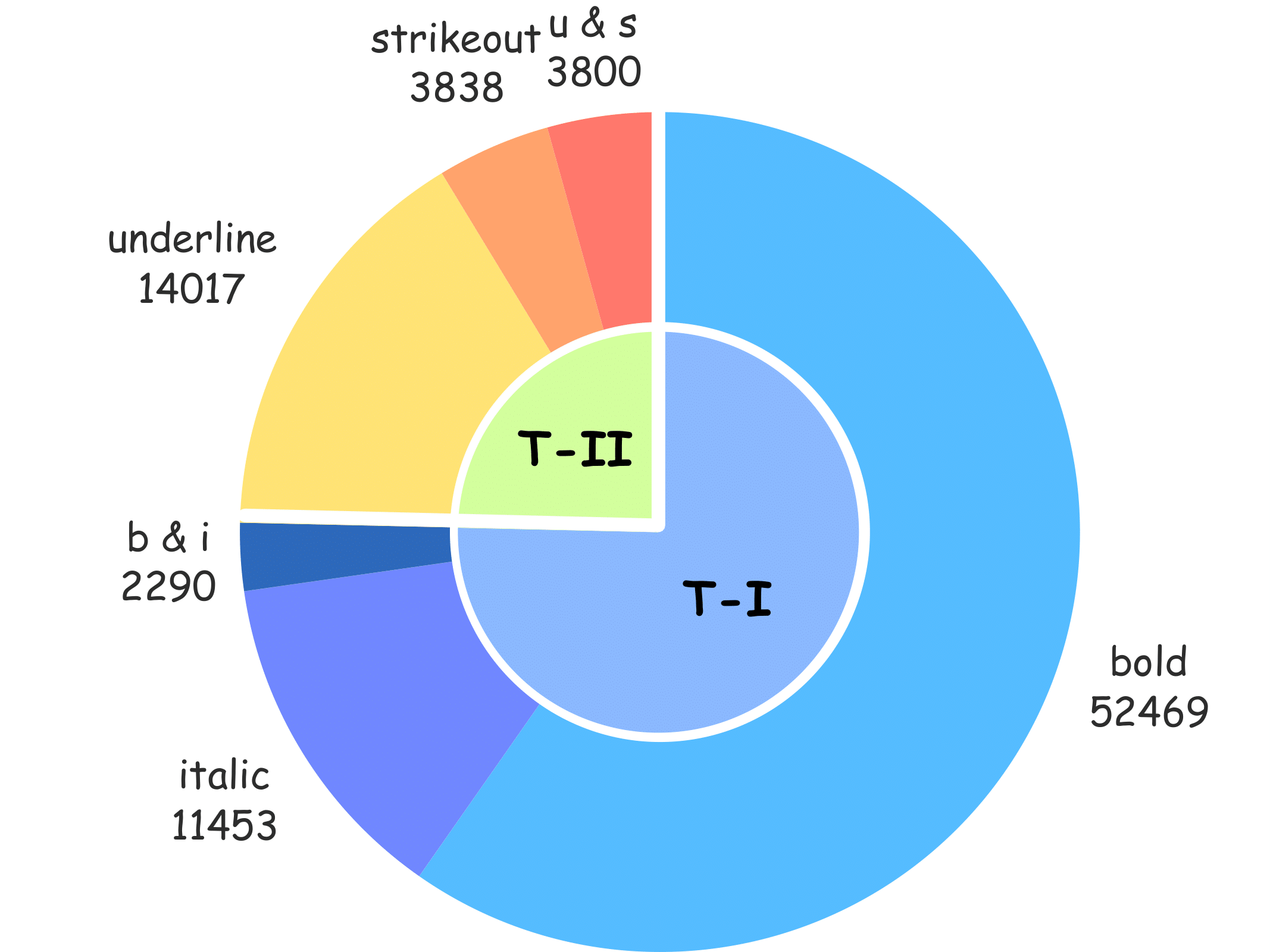
context for more accurate predictions. We also present MMTAD,
a diverse multilingual dataset annotated with text attributes across real-world
documents. TexTAR achieves state-of-the-art performance in extensive evaluations.
TexTAR – Textual Attribute Recognition in Multi-domain and Multi-lingual Document Images
Accepted at ICDAR 2025 (ORAL)
Rohan Kumar ·
Jyothi Swaroopa Jinka ·
Ravi Kiran Sarvadevabhatla
International Institute of Information Technology Hyderabad